This lecture will build on the ideas you saw in lecture 5 and focus on examples that explore some of the key concepts from that lecture. These include the ideas of context, messages and sub-flows. The examples in this lecture are a little more complex than previous examples – mainly in the sense that the function nodes are more complex – but are still kept as clean and simple as possible.
| We use a cloud hosted version of Node-RED for these lectures called FRED. Sign up for a free account at FRED. Examples in the early lectures will work with other installations of Node-RED, later lectures use nodes you will need to install yourself if you don’t use FRED. |
Examples
(Click to go directly to the example)
Example 6.1 Retrieving data from a web page
Example 6.2 Counting words in a string
Example 6.3 Using context to generate rolling averages
Example 6.5 Defining and using an iterator sub-flow
Example 6.6 Getting earthquake data from an external API and returning it as multiple messages
Example 6.7 Multiple inputs on a function node
Example 6.8 Letting a function node send multiple messages on a single output
Example 6.9 Creating a Blog Site With Node-RED
Example 6.1 Retrieving data from a web page
Let’s write a flow that scrapes the latest stock market indices from google at http://google.com/finance and format it using a function node. If you inspect the page shown in Figure 6.1 using the Chrome browser’s ‘Inspect Element’, you’ll find that the three indices have the same td.bld span tag. This tag can be used to retrieve all three indices with the html node. You’ll set up an inject node to trigger an http request to get the page, then the html node to get the elements with the td.bld span tag.
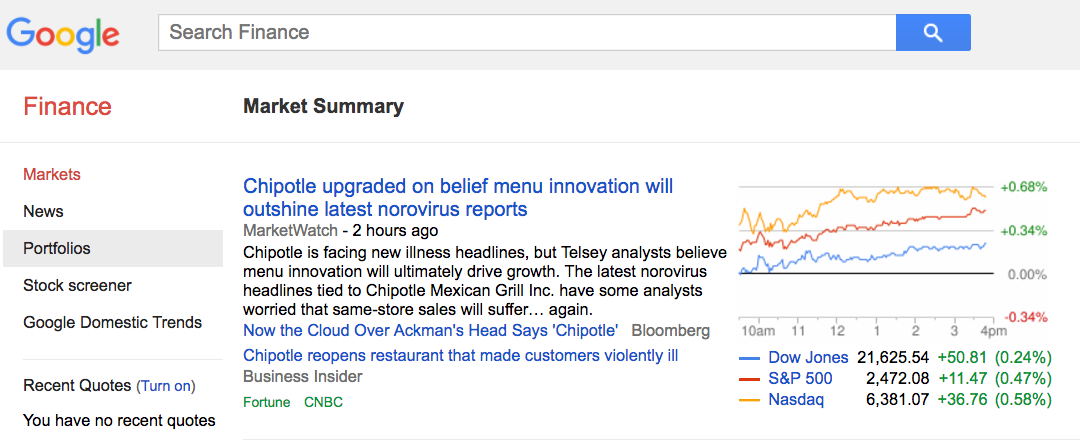 Figure 6.1 Stock market index page from Google.
Figure 6.1 Stock market index page from Google.
Configure the http node and html nodes as shown in Figure 6.2
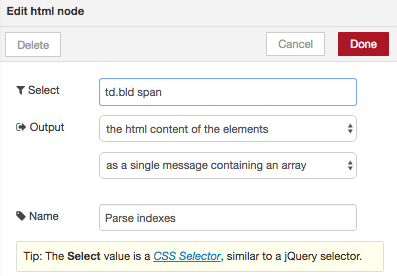
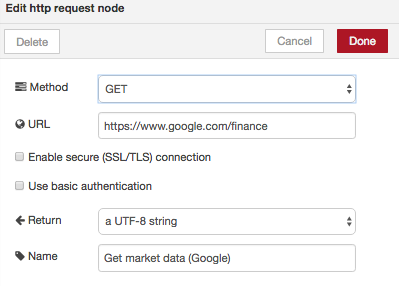
Figure 6.2 Configuration of http and html nodes to retrieve stock indices from Yahoo.
Then wire them up as shown in Figure 6.3, with a debug node to show the output.
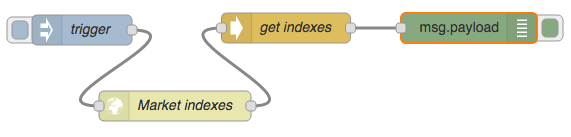
Figure 6.3 Flow to retrieve the market indexes.
The output should contain the latest index values. When you click on the ‘trigger’ inject node, you will see the following in the debug pane:
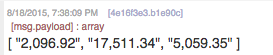
Figure 6.4 Stock indices as array of strings.
That was easy, but what you really want is an array of JSON name:value pairs that uses the name to describe the values and shows the values as numbers:
Listing 6.1 Desired JSON output of stock indices
- [{
- “index”:”S&P”,
- “value”:2096.92
- },{
- “index”:”Dow”,
- “value”:17511.34
- },{
- “index”:”Nasdaq”,
- “value”:5059.35
- }]
Let’s write a function node to format this the way you want it. Take a look at Listing 6.2. Line 1 takes the incoming stock prices and stores them in an array prices and then creates two new arrays, one to hold the output messages and the other to hold the textual name of the three different indices. Lines 5-8 loop through the incoming stock indices and for each one pushes a name:value pair to the output message array. At Line 8, you use the JavaScript replace function to remove all commas from the index values before parsing them as numbers. Let’s call this function format indices.
Listing 6.2 Function node code to format stock indices
- msg.headers = msg.originalHeaders;
- var prices = msg.payload;
- var newPayload = [];
- var priceIndex = [‘S&P’,’Dow’,’Nasdaq’];
- for ( var i=0; i<prices.length; i++) {
- newPayload.push({
- index:priceIndex[i],
- value:Number(prices[i].replace(/,/g,”))
- });
- }
- msg.payload = newPayload;
- return msg;
Now wire this into your flow as shown in Figure 6.5.
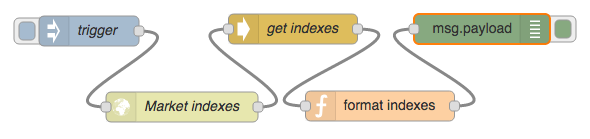
Figure 6.5 Complete market index flow.
Once you deploy and test, your debug console should output something similar to Figure 6.6. The data now looks good and you can use this format for downstream nodes in your flow.

Figure 6.6 Debug output from new flow.
BACK to main Lecture 6
PREVIOUS example NEXT Example
About Sense Tecnic: Sense Tecnic Systems Inc have been building IoT applications and services since 2010. We provide these lectures and FRED, cloud hosted Node-RED as a service to the community. We also offer a commercial version to our customers, as well as professional services. Learn more.
© Lea, Blackstock, Calderon

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.